Working Rules of Bioinformatics in Drug Discovery: What Every Biotech Professional Must Know

Introduction
Drug discovery isn't just about finding new molecules anymore — it's about how intelligently we use data to guide that discovery. In an era where a single drug can cost over $2.6 billion to develop and take 10-15 years to reach patients, computational efficiency isn't just helpful — it's essential for survival in the pharmaceutical industry.
That's where bioinformatics rules come in. These aren't arbitrary regulations, but proven frameworks that transform raw biological data into actionable drug discovery insights. While most professionals focus on learning individual tools like BLAST, molecular docking software, or machine learning algorithms, the real competitive advantage lies in understanding the strategic rules that govern how these tools work together.
This comprehensive guide expands on the concepts we introduced in our LinkedIn newsletter about the hidden rules of bioinformatics. If you missed that overview, we recommend reading "The Hidden Rules: How Bioinformatics Powers Drug Discovery in 2025 and Beyond" first.
By the end of this article, you'll understand not just how to use bioinformatics tools, but how to apply the underlying rules that make computational drug discovery both reliable and scalable in real-world pharmaceutical environments.
Why Rules Matter in Bioinformatics
The biggest misconception among students and early-career professionals is confusing tools with processes. Learning to run RNA-Seq analysis or perform molecular docking is like learning to use a microscope — it's a valuable skill, but it doesn't automatically make you a researcher. The transformative power comes from understanding when, why, and how to apply these tools systematically.
Consider this scenario: two bioinformaticians analyze the same dataset using identical tools. One follows established validation rules, maintains proper data provenance, and applies systematic quality control. The other skips validation steps to get faster results. Months later, when experimental validation begins, only the first analysis holds up under scrutiny. The difference wasn't in tool selection — it was in rule adherence.
Reproducibility forms the foundation of reliable bioinformatics. In drug discovery, computational predictions guide million-dollar experimental decisions. If your analysis can't be reproduced by colleagues, it's worthless regardless of how sophisticated your algorithms are. Rules ensure that every analysis step is documented, every parameter is justified, and every result can be independently verified.
Validation protocols prevent computational errors from propagating through expensive experimental phases. A poorly validated computational model might suggest a promising drug target that fails in cell culture, wasting months of medicinal chemistry effort. Rules establish systematic approaches to validate computational predictions against known data before applying them to novel problems.
Standard pipelines enable collaboration and knowledge transfer across teams. When everyone follows the same rules for data preprocessing, analysis, and reporting, computational work becomes modular and scalable. New team members can quickly understand and build upon existing work, dramatically accelerating project timelines.
The Data Workflow in Drug Discovery
Understanding the complete data workflow is crucial for applying bioinformatics rules effectively. Each step has specific requirements, validation criteria, and integration points that govern how computational work supports experimental drug discovery.
Step 1: Data Collection
Data collection in drug discovery spans multiple sources: genomic databases like TCGA for patient samples, chemical databases like ChEMBL for known drug-target interactions, structural databases like PDB for protein conformations, and proprietary experimental data from internal screening campaigns. The cardinal rule: establish data provenance from day one. Every dataset must include metadata describing its source, collection methods, quality metrics, and any preprocessing steps applied before analysis.
Quality assessment begins at collection. Genomic data requires checking sample purity, sequencing depth, and batch effects. Chemical data needs validation for molecular structure accuracy and bioactivity measurement consistency. Protein structural data must be evaluated for resolution, completeness, and experimental conditions. Poor quality data at input guarantees poor results at output, regardless of analytical sophistication.
Step 2: Data Preprocessing & Quality Control
Raw biological data is rarely analysis-ready. Preprocessing rules ensure consistent data formats, remove systematic biases, and flag potential quality issues before downstream analysis. For genomic data, this includes read trimming, adapter removal, and quality score filtering. For chemical data, standardizing molecular representations, removing duplicates, and flagging reactive compounds. For structural data, validating geometries and identifying missing residues.
Quality control metrics must be established for every data type. Genomic QC includes alignment rates, insert size distributions, and coverage uniformity. Chemical QC involves molecular weight distributions, structural alerts, and bioactivity ranges. Structural QC encompasses resolution statistics, refinement metrics, and validation scores. Document QC results systematically — they inform analysis parameters and help troubleshoot unexpected results later.
Step 3: Target Identification
Target identification combines multiple data sources to prioritize proteins for drug development. Genomic data reveals targets overexpressed in disease, pathway analysis identifies key regulatory nodes, and literature mining uncovers validation evidence. The integration rule: no single data source is sufficient for target validation. Convergent evidence from multiple approaches builds confidence in target selection.
Scoring frameworks systematically evaluate target attractiveness based on biological relevance, druggability predictions, competitive landscape, and development feasibility. Each criterion requires specific validation rules. Biological relevance needs pathway analysis and disease association studies. Druggability assessment requires pocket analysis and chemical space evaluation. Competitive analysis involves patent landscaping and clinical trial monitoring.
Step 4: Virtual Screening
Virtual screening applies computational methods to identify potential drug compounds from large chemical libraries. Structure-based screening uses molecular docking to predict binding poses and affinities. Ligand-based screening employs similarity searches and pharmacophore matching to find compounds resembling known active molecules. The selection rule: combine multiple screening approaches to capture diverse chemical mechanisms.
Validation protocols are essential for virtual screening success. Docking algorithms must be benchmarked against known active compounds for the target of interest. Scoring functions require calibration using experimental binding data. Hit lists need systematic filtering to remove pan-assay interference compounds, reactive molecules, and compounds with poor drug-like properties.
Step 5: Lead Optimization
Lead optimization iteratively improves initial hit compounds through structure-activity relationship analysis. Computational methods predict how chemical modifications affect potency, selectivity, and drug-like properties. Free energy perturbation calculations estimate binding affinity changes. ADMET prediction models assess absorption, distribution, metabolism, excretion, and toxicity properties.
The optimization rule: balance multiple objectives simultaneously. Improving potency while maintaining selectivity, enhancing drug-like properties while preserving synthetic accessibility. Multi-parameter optimization requires systematic design strategies and statistical analysis of structure-activity data. Document all design rationales — they inform future optimization cycles and help interpret unexpected results.
Step 6: Validation & Feedback Loop
Experimental validation tests computational predictions in biochemical and cellular assays. Results feed back into computational models, improving their accuracy for future predictions. The feedback rule: systematic comparison of computational predictions with experimental results identifies model strengths and limitations. This analysis guides model refinement and establishes confidence intervals for future predictions.
Validation data must be systematically captured and integrated into computational workflows. Binding affinity measurements validate docking scores and free energy calculations. Cell-based assay results test ADMET predictions and toxicity models. Animal study data validates pharmacokinetic predictions and efficacy models. This feedback enables continuous improvement of computational approaches.
Tools vs. Rules – What's the Difference?
The distinction between tools and rules is fundamental to professional bioinformatics practice. Tools are software applications, algorithms, and computational methods. Rules are the principles, protocols, and frameworks that govern how these tools are applied effectively in drug discovery contexts.
Data Collection Tools include database APIs, web scraping scripts, and data management platforms. Data Collection Rules encompass provenance tracking, quality assessment protocols, and metadata standards. The tools extract data; the rules ensure data integrity and usability for downstream analysis.
Analysis Tools span sequence aligners, molecular docking software, machine learning libraries, and statistical packages. Analysis Rules include parameter validation, statistical significance criteria, and result interpretation frameworks. Tools perform calculations; rules ensure calculations are meaningful and reliable.
Visualization Tools create plots, molecular graphics, and interactive dashboards. Visualization Rules govern chart selection, statistical representation, and audience-appropriate presentation. Tools generate graphics; rules ensure graphics communicate insights accurately and effectively.
Integration Tools include workflow managers, pipeline frameworks, and data integration platforms. Integration Rules establish data flow protocols, error handling procedures, and quality checkpoints. Tools connect analyses; rules ensure connections are robust and maintainable.
The key insight: tools are commodities that anyone can learn, but rules represent strategic knowledge that creates competitive advantage. Mastering rules enables you to select appropriate tools, configure them correctly, and integrate them effectively for specific drug discovery challenges.
RNA-Seq, Docking, & AI: Rule-Based Integration
Modern drug discovery increasingly relies on integrating multiple computational approaches. Success requires understanding not just individual methods, but the rules governing their effective combination. Let's examine three critical integration scenarios.
RNA-Seq Data Integration Rules
RNA-Seq analysis in drug discovery follows strict normalization and validation protocols. Normalization rules ensure comparable expression measurements across samples and studies. TPM (Transcripts Per Million) normalization accounts for transcript length differences, while quantile normalization removes systematic biases between samples. The integration rule: always validate normalization effectiveness using spike-in controls and known housekeeping genes.
Statistical validation rules prevent false discoveries in differential expression analysis. Multiple testing correction accounts for analyzing thousands of genes simultaneously. Effect size thresholds ensure biological significance beyond statistical significance. Replication requirements mandate sufficient biological replicates for reliable conclusions. These rules transform raw sequencing data into reliable biomarker candidates.
Integration with drug response data requires careful temporal and dosage considerations. Gene expression changes occur at different timescales than phenotypic responses. Early transcriptional changes might predict later cellular responses, but this relationship must be validated systematically. The temporal rule: align expression measurements with relevant biological endpoints for meaningful correlation analysis.
Molecular Docking Integration Rules
Molecular docking success depends on systematic protocol selection and validation. Rigid vs. flexible docking rules depend on target characteristics and computational resources. Rigid docking works well for screening large compound libraries against well-characterized binding sites. Flexible docking provides more accurate predictions for targets with conformational flexibility but requires significantly more computational resources.
Scoring threshold rules balance sensitivity and specificity in hit identification. Overly permissive thresholds generate too many false positives for experimental follow-up. Overly restrictive thresholds miss potentially interesting compounds. The calibration rule: establish scoring thresholds using known active and inactive compounds for each target, then validate threshold performance on independent test sets.
Integration with experimental data requires systematic validation protocols. Docking predictions must correlate with biochemical binding measurements across diverse compound series. Structure-activity relationships from docking should match experimental SAR data. The validation rule: never trust docking results without experimental correlation analysis using compounds spanning multiple orders of magnitude in activity.
AI/ML Integration Rules
Artificial intelligence and machine learning applications in drug discovery require rigorous validation frameworks. Dataset splitting rules prevent overfitting and ensure model generalizability. Training sets build models, validation sets guide hyperparameter optimization, and test sets provide unbiased performance estimates. The temporal rule: when possible, use chronological splitting to mimic real-world prediction scenarios.
Cross-validation protocols assess model stability and reliability. K-fold cross-validation provides multiple performance estimates, while leave-one-out validation tests sensitivity to individual data points. Stratified sampling ensures balanced representation across different compound classes or activity ranges. The robustness rule: model performance should be consistent across multiple validation approaches.
Ethical data handling rules become increasingly important as AI models influence drug development decisions. Data privacy requirements protect patient information in genomic datasets. Bias detection protocols identify and mitigate systematic errors in training data. Transparency standards ensure model predictions can be interpreted and validated by domain experts. The accountability rule: AI predictions must be explainable and auditable for regulatory approval processes.
Case Study Examples
To illustrate rule-based bioinformatics integration, let's examine a simplified but realistic case study: using RNA-Seq and molecular docking together to identify a cancer drug target and optimize lead compounds.
Background and Target Identification
Our hypothetical project focuses on identifying novel therapeutic targets for triple-negative breast cancer (TNBC), an aggressive subtype with limited treatment options. We begin by applying RNA-Seq analysis to compare TNBC tumor samples with normal breast tissue, following established rules for cancer genomics analysis.
Data Collection Rules Applied: We access TCGA breast cancer data, including 150 TNBC samples and 20 normal tissue controls. Metadata includes patient demographics, tumor staging, treatment history, and survival outcomes. Quality control reveals consistent RNA integrity numbers (RIN > 7) and adequate sequencing depth (>30M reads per sample). We exclude samples with obvious batch effects or technical anomalies.
Analysis Rules Applied: Differential expression analysis using DESeq2 identifies 2,847 significantly upregulated genes in TNBC samples (FDR < 0.05, log2FC > 2). We apply pathway enrichment analysis using KEGG and GO databases, revealing enrichment in cell cycle regulation, DNA repair mechanisms, and metabolic reprogramming pathways. Cross-validation against independent TNBC datasets confirms 78% overlap in top differentially expressed genes.
Target Prioritization Rules: We score potential targets using multiple criteria: expression fold change, pathway centrality, druggability prediction, and literature validation. CDK4 (Cyclin-Dependent Kinase 4) emerges as a high-priority target: 4.2-fold upregulated in TNBC, central node in cell cycle networks, established druggability with available crystal structures, and extensive validation literature supporting its role in cancer progression.
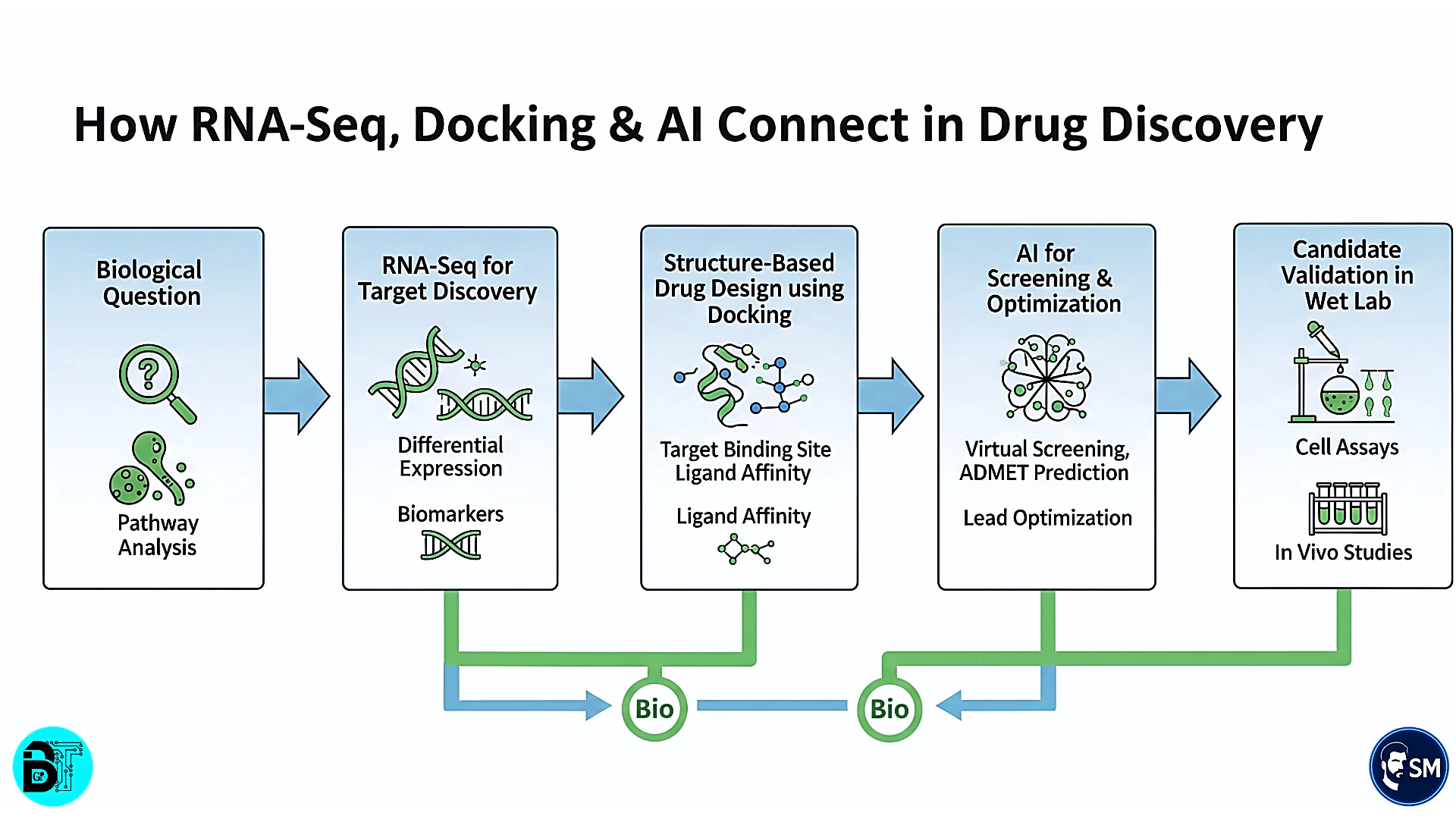
Structure-Based Drug Design Integration
With CDK4 validated as our target, we transition to structure-based drug design using molecular docking approaches. This integration requires careful application of docking rules and validation protocols.
Structure Preparation Rules: We obtain high-resolution crystal structures of CDK4 from the Protein Data Bank, selecting structures with resolution better than 2.5Å and complete active site coverage. Structure preparation includes hydrogen addition, side chain optimization, and binding site definition. We generate multiple receptor conformations to account for protein flexibility during compound binding.
Virtual Screening Rules: We screen the ChEMBL database containing 2.1 million drug-like compounds against our CDK4 structures. Docking protocol validation using known CDK4 inhibitors achieves 85% success rate in reproducing experimental binding poses. We establish scoring thresholds based on known active compound distributions, selecting the top 0.1% of compounds (approximately 2,100 molecules) for further analysis.
Hit Validation Rules: Selected compounds undergo systematic filtering: removal of pan-assay interference compounds (PAINS), reactive functional groups, and molecules violating Lipinski's rule of five. Structure-activity relationship analysis identifies common pharmacophores among high-scoring compounds. We prioritize 50 compounds representing diverse chemical scaffolds for experimental validation.
Experimental Integration and Feedback
The final phase integrates computational predictions with experimental validation, applying feedback rules to improve future predictions.
Biochemical Validation Results: Experimental testing reveals 12 compounds with CDK4 binding affinity better than 10μM, representing a 24% hit rate from computational screening. Structure-activity analysis shows a strong correlation (R² = 0.73) between docking scores and experimental binding affinities, validating our computational approach.
Cell-Based Validation Rules: We test active compounds in TNBC cell lines, measuring both CDK4 inhibition and cellular proliferation effects. Results reveal 4 compounds with nanomolar CDK4 activity and significant anti-proliferation effects. Selectivity profiling against related kinases identifies 2 compounds with >100-fold selectivity for CDK4 over CDK1, CDK2, and CDK6.
Integration with RNA-Seq Data: We treat TNBC cells with our lead compounds and perform RNA-Seq analysis to assess transcriptional responses. Gene expression changes confirm on-target CDK4 inhibition: downregulation of cell cycle genes, upregulation of cell cycle checkpoint pathways, and minimal off-target transcriptional effects. This integration validates both our target identification and compound mechanism of action.
Feedback Loop Implementation: Experimental results guide computational model refinement. Binding affinity data improves docking score calibration for future screening campaigns. Structure-activity relationships inform pharmacophore models for lead optimization. Selectivity data guides virtual library design for next-generation compounds. This systematic feedback ensures the continuous improvement of our computational approaches.
Explore the Full Concept in Our Newsletter
Want a simplified overview? This detailed guide builds upon concepts we introduced in our LinkedIn newsletter. If you prefer a concise summary of these ideas, check out our LinkedIn edition: The Hidden Rules of Bioinformatics in Drug Discovery for a quick overview that you can share with colleagues and save for reference.
Looking for hands-on tutorials? Our companion article "How to Set Up and Execute an RNA-Seq Analysis Project: A Step-by-Step Beginner's Guide" provides detailed technical instructions for implementing the RNA-Seq workflows discussed in this case study. Perfect for students and early-career professionals who want to build practical skills alongside strategic understanding.
Need career guidance? Visit our BTGenZ Career Hub for personalized advice on building bioinformatics skills, preparing for industry interviews, and advancing your computational biology career. We provide tailored guidance based on your background, goals, and target industry sectors.
Start Building Your Bioinformatics Career with These Foundations
Understanding bioinformatics rules provides a significant competitive advantage in today's biotech job market. While many candidates can demonstrate tool proficiency, few can articulate the strategic principles that govern tool application in real-world drug discovery contexts.
For Internship Applications: Employers value interns who understand project workflows, not just individual analyses. Demonstrating knowledge of validation protocols, quality control standards, and integration strategies signals that you can contribute meaningfully to ongoing projects from day one. Include specific examples of rule-based approaches in your cover letters and interviews.
For PhD Programs: Graduate school success requires independent research capabilities, which depend heavily on understanding methodological principles rather than just technical procedures. Students who grasp the rules behind their analyses can troubleshoot problems, adapt methods to new contexts, and design innovative approaches that advance their research fields.
For Industry Positions: Pharmaceutical companies desperately need bioinformatics professionals who can think strategically about computational workflows. Entry-level positions increasingly require an understanding of how computational predictions integrate with experimental validation cycles. Senior roles demand the ability to design and implement rule-based frameworks that ensure reproducibility and reliability across entire research organizations.
Salary Impact: Professionals who understand strategic bioinformatics principles command significantly higher salaries than those with purely technical skills. According to recent industry surveys, computational biologists with workflow design experience earn 20-35% more than peers with equivalent technical backgrounds but limited strategic knowledge.
How We Can Help: Our personalized consultancy services help biotech professionals develop the strategic thinking skills that employers value most. We provide tailored guidance on building project portfolios, preparing for technical interviews, and positioning your experience for maximum career impact. Whether you're transitioning from academia to industry or advancing within pharmaceutical companies, we help you leverage bioinformatics rules for career acceleration.
Mastering Tools Is Just the Start — It’s the Understanding That Pays Off
The pharmaceutical industry stands at an inflection point. Traditional drug discovery approaches are too slow and expensive for modern healthcare challenges. Computational biology offers solutions, but only when applied systematically according to proven rules and validated frameworks.
Tools are becoming commoditized — cloud platforms make sophisticated algorithms accessible to everyone. The competitive advantage now lies in understanding the strategic principles that govern how these tools work together effectively. Rules transform individual analyses into integrated workflows that reliably generate actionable insights for drug discovery.
Students and early-career professionals who master these rules position themselves at the forefront of computational drug discovery. They become the bridge between cutting-edge computational methods and practical pharmaceutical applications. They design workflows that others follow, establish standards that teams adopt, and create frameworks that accelerate drug development across entire organizations.
The transformation begins with understanding: Tools are easy to learn, but rules require deep comprehension of how computational biology serves drug discovery objectives. Rules demand understanding of biological contexts, experimental constraints, and business requirements that govern pharmaceutical research.
The transformation continues with application: Rules without implementation remain academic exercises. True mastery comes from applying rule-based approaches to real drug discovery challenges, learning from validation results, and continuously refining computational strategies based on experimental feedback.
The transformation culminates in leadership: Professionals who understand bioinformatics rules become the architects of next-generation drug discovery platforms. They design the computational infrastructure that accelerates therapeutic development, establish the quality standards that ensure regulatory compliance, and create the integration frameworks that enable truly interdisciplinary research.
Your journey from tool user to rule master begins now. The pharmaceutical industry needs professionals who can navigate the complexity of modern computational drug discovery while maintaining the rigor required for therapeutic development. Will you be among those who transform how we discover life-saving medicines?
Frequently Asked Questions
Founder of BTGenZ. Passionate about simplifying biotechnology for the next generation and bridging the information gap for aspiring biotechnologists in India.

Related Reads
Engage with Our Community
Join the conversation and share your thoughts with the BTGenZ community!
Connect on LinkedInLoading commenting section...
Comments Section
No approved comments yet. Be the first to leave a comment!